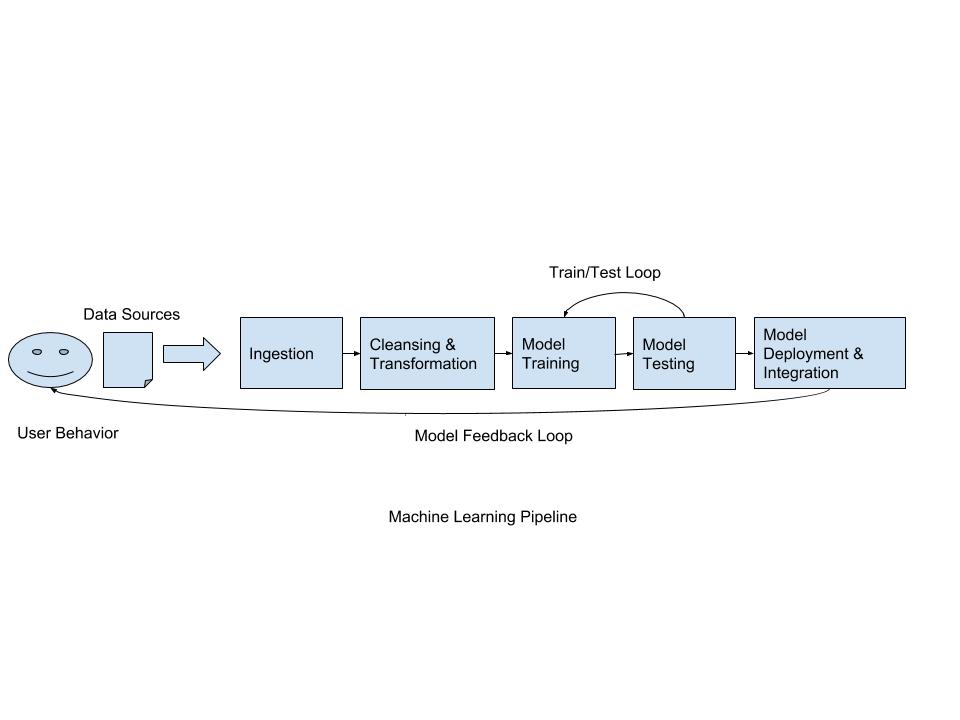
The below outlines some areas for feature engineering that could be applied using various machine learning and deep learning techniques. There is also options here to build significant robots or drones.
In-Store Analytics (conversion of customers when in the store)
- sentiments of customers
- product vs purchase stock history
- order fulfillment
- stock and inventory monitoring
- loyalty promotions
- personalization
- helping customers find bargains
- identifying customer shopping basket history
- maximization of conversion
- shelving analysis what product gets bought more next to what product
- supply-chain on-demand by product (product just bought, re-shelf, check stock availability)
- curiosity shopping conversion
- price analytics
- offer tracking
- streaming offers for loyalty customers
- ereceipts
- discount tiers (more customer buys the more discounts they get)
- targeting age group buying habits
- semantic search relevance
- customer agents
- cashier agents
- warehouse agents
- morelikethis
- track customer experience
- deep insights on product recommendations (i like this heel, this color, this buckle, perfect!)
- nutritionist/wellness agents (people that are positively conscientious of their health)
- product tabs
Out-Store Analytics (People passing outside the store)
- competitor Insights (is the product cheaper at Y retailer, is the product available at X retailer)
- insight on window dressing (engage the right window dressing to attract customers)
- insights on social media/viral marketing
- promotions
- augmented reality (customers can check product availability at X retailer, price, promotions, etc)
- lead generation
- product trends
- reviews
- social sentiment about the store/identify why the customer does not enter the store
- effectiveness of advertising to conversion ratio
- local store optimization (location)
Types of customers:
- Curiosity/Bargain Shoppers
- Spendthrift/Impulse Shoppers (heavy shopping one day, no shopping the next - mood swingers)
- Loyalty/Informed Shoppers
- Indecisive Shoppers
- Wanderers
- Complainers
- Green Shoppers (Vegans, Weight Watchers, Calorie/Nutrition, Organic, Free Range, Gluten-Free, Religious)
Other Areas:
- Time of Day (night, morning, afternoon, weekday, weekend, bank holiday)
- Product Categorization and Labeling
- Teens
- Professionals
- Parents
- Pensioners
- Students
- Tourist
- Singles
- Kids
Core Areas of Retail Analytics:
- In-Store (local user experience)
- Out-Store (local user experience)
- Ecommerce (online user experience)
- Home Delivery (remote user experience)
- Supply-Chain & Logistics (inventory/product/stock/transportation/warehousing)
- Pricing/Loyalty (core sales/loyalty user experience/competition)
- Contextual Advertising (core marketing)
- Social Media/Rumor Mill (Sentiment Analysis - Reviews/Brand/Product/Event/Experience)
- Recruitment (staffing)
- Geographical (Locational/Regulatory Compliance)
- Security (Local/Online/Remote)
- CRM (core 360)
Key In-Store Q’s for Analytics:
- Shrinkage - shoplifters/theft/weak links
- Managing the Moment - achieving customer needs in real-time
- Measure Customer In-store experience (wants/needs/desires)
- What drives sales conversion
- What is not in the basket
- Feedback on Promotions/Effectiveness of Promotions
- Complex Data Insights/Summaries
- Information on ROI - Return on Investment
- Optimization for Product Mix - What moves the Shopper to Purchase
- Shopper vs Buyer